常模的功用
常模指特定參照團體測驗上的平均分數或表現,常模是解釋測驗結果的參照依據,測驗分數必須與常模比較,以顯示其在所屬團體中的相對位置。
常模具有兩大功用:
- 指出受測者分社在常模團體中的項對位置
- 提供比較的量數,使個人在不同測驗上的得分數可以互相比較
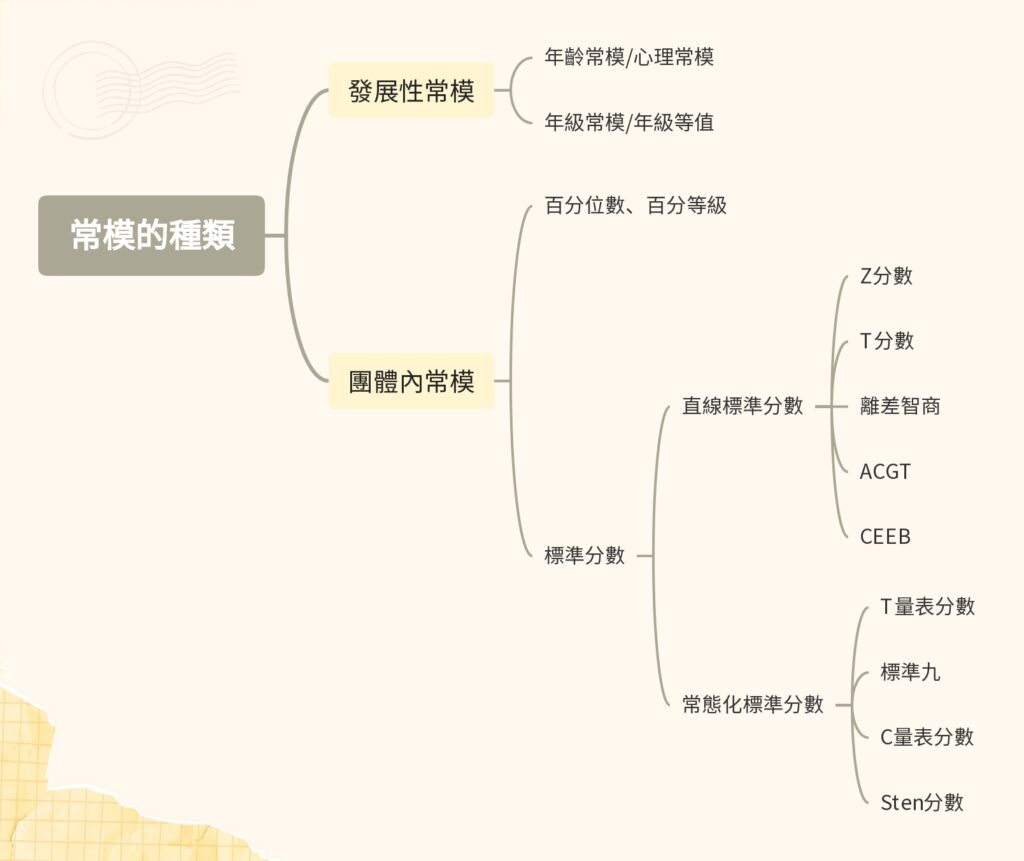
發展性常模
依據個人所獲得的發展水準來表示的分數,稱為發展性常模,可用來說明個人在發展歷程中的成熟水準。
(一)年齡常模或心理年齡
- 解釋:以特定年機層的平均表現水準做為比較基準的一種方法。
個別受試者的原始分數轉換成年齡當量,例如:年齢當量為10歲,代表這個受試者的得分相當於10歲兒童的平均水準),然後比較這個受試者的年齢當量與他實際年齡 (實足年齡) 的差別。 - 例如:Stern的比率智商、比西量表
- 特色與限制:年齡常模適用於隨年齡而增長的特質,如身高、體重、智力、學習成就等 。其限制是心理特徵的生長,各年齡階段並不一致 (年齡單位隨年齡增加而減少),而且不同生理年齡兒童,即使得到相同的心理年齡也不代表具有相同的心理能力或技巧。
(二)年紀常模或年級等值
- 解釋 :年級當量的概念與年齡當量類似,只是把受試者的原始分數轉換成相應的年級 。年齡當量是受試者的表現相當於幾歲;年級當量則是受試者的表現相當於幾年級。
- 例如:四年級兒童閱讀測驗得到六年及閱讀測驗的年級等值,代表該兒童閱讀能力相當於六年級程度。
- 特色與限制:年級常模的特色是適用於隨年級而增加的特質,如閱讀、算術、語言等。且易使學生、家長及施測人員了解。限制則為 :(1)年級常模的單位未必相等,例如年級等值3 至4的差距,未必等於6至7的差距,或許後者因為難度增加,反而成長幅度更大;(2)得到的年級等值不代表完全具有該年級的能力,例如四年級兒童閱讀測驗上得到六年級的年級等值,並不代表學會六年級的所有閱讀內容,或具備六年級的所有閱讀能力
團體內常模
團體內常模:依據一個人在所屬團體中的相對位置所表示的分數,又稱作組內常模。藉此參照可了解個別受測者在全體受測者中的相對位置,協助解釋測驗結果。主要有兩大類:百分位數/百分等級;標準分數。
(一)百分位數和百分等級
百分等級(Percentile rank; PR)是表示標準化測驗結果時最常用的衍生分數。它是指得到某一原始分數的人,在參照團體中能贏過百分之多少的人。
優點:容易了解;發展常模通常只適用於兒童,百分等級可適用於所有年齡。
缺點:原始分數轉换成百分等級容易失真。原始分數靠近平均的人很多,因此在平均附近原始分數差幾分,會造成百分等級(PR)劇烈的改變;而在高分及低分區,同樣差幾分 ,PR 值的變化小得多。
百分等級是次序量尺(非等距量尺),無法進行四則運算。
(二)標準分數
標準分數係以平均數為參照點,用離均差的數值表示測驗分數在所屬團體中的相對位置。z 分數(z Score) 是最典型的標準分數,其他的標準分數皆建立於z 分數的基礎上。
1.直線標準分數
統計中常見的直線轉換是將原始分數經過直線方程式 (二元一次方程式)代換成另一個新分數。且直線轉換前後,峰度與偏態情形不會改變。
Z分數
z分數是最簡單,也是最基本的標準分數,它是以標準差為單位,來說明某一原始分數是位於平均數以上或以下幾個標準差的位置上。它是將每個原始分數減去一常數(平均數),再除以一常數(標準差)的直線轉換方式變成一組以平均數為 0,標準差為 1 的標準分數。
轉換後的分數有99%是落在+3.0到-3.0之間, z分數因為有一半的分數是負的,且常帶有小數,與一般人對分數的概念不同,很難溝通;所以除了對專業人員外,一般都用其他的標準分數來報導。許多其他的標準分數都是以 z分數為基礎作第二次的直線轉換。下列的線性標準分數就是利用Z分數再做一次直線轉換的。
T 分數
T 分數是最早出現的二次轉換標準分數,它將每一 z分數乘以10,以消除小數;再將每一 z分數加上50,以消除負數。它是轉換成以平均數為50,標準差為10的標準分數。
離差智商
早年所謂的智商是比率智商 (ratio IQ),它是心理年齡和實足年齡的比值。而離差智商(Deviation IQ., DIQ)才是現代各種智力測驗所常用的分數系統,它是轉換成以平均數為100,標準差為15(如:魏氏智力量表)的標準分數。
AGCT分數
AGCT分數是美國陸軍普通分類測驗(Army General Classification Test)所用的標準分數系統,其他性向測驗(如通用性向測驗GATB)也採用。它是轉換成以平均數為100,標準差為20的標準分數
CEEB分數(或稱ETS分數)
CEEB分數是美國大學入學考試委員會(College Entrance Examination Board)所使用的一種分數系統,而美國測驗服務社(Educational Test Service)的各類大型測驗(如:SAT、GRE、TOEFL等)也使用此一分數系統來報導測驗結果。它是轉換成以平均數為500,標準差為100的標準分數。由於大型測驗中受測人數多,擴大標準差和平均數的數值可以大量減少同分的人數。
2.常態化標準分數(面積轉換)
常態化標準分數(normalized standard scores)的轉換方式不是採用直線轉換,而是採用面積轉換(area transformation),其轉換步驟如下:
- 先就每一個原始分數,依據到其組中點的累積人數,換算成百分等級。
- 使用「常態分配下z分數與百分等級對照表」查出與該百分等級對應的z分數。另一方法是把百分等級除以100,化成小數,把它當作常態曲線下不同z分數左端的面積,然後查「z分數與常態曲線下面積對照表」,找出其對應的z分數。
- 利用查表所得的 z分數經由前述之公式再轉換成T分數、AGCT分數、離差智商等。
直線轉換是直接以平均數、標準差來求 z分數,所以原始分數的分配若是偏態的,經轉換後的標準分數分配仍是偏態的。但是常態化轉換是先換成百分等級,再查表換成在常態分配下對應的 z分數,所以經轉換後的標準分數的分配一定是常態的。
T量表分數
「T量表分數」是常態化標準分數之一種,為麥柯爾(W. A. McCall)於1922年創用的。這種分數與T分數一樣,是以50為平均數,10為標準差的轉換分數;其不同處在量表分數是經過常態化轉換,而T分數只是經過直線轉換。
標準九
標準九(Stanine score)是把所有的分數簡化成九個等級,而每一個等級所佔的人數比例是按照常態分配的原理來指派的。標準九、標準十、C量表分數都是以標準分數的樣式呈現,但在換算上是依據贏過人數百分比及常態分配原理而來,所以又稱為「常態化標準分數」(Normalized standard score),其中又以標準九最為常用。
轉換後等第 1 2 3 4 5 6 7 8 9
百分比 4% 7% 12% 17% 20% 17% 12% 7% 4%
累積百分比 4% 11% 23% 40% 60% 77% 89% 96% 100%
C量表分數
量表分數(C-Scaled score)除了兩端各多出一個等第(0 和 10)之外,其餘與標準九相同。
| 轉換後等第 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 百分比 | 1% | 3% | 7% | 12% | 17% | 20% | 17% | 12% | 7% | 3% | 1% |
| 累積百分比 | 1% | 4% | 11% | 23% | 40% | 60% | 77% | 89% | 96% | 99% | 100% |
Sten score
Sten score和標準九類似,是左右各五個單位的常態化標準分數。
| 轉換後等第 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 百分比 | 2% | 5% | 9% | 15% | 19% | 19% | 15% | 9% | 5% | 2% |
| 累積百分比 | 2% | 7% | 16% | 31% | 50% | 69% | 84% | 93% | 98% | 100% |
常模種類
一份廣為使用的測驗通常會就全國範圍内做大規模的抽樣,形成樣本團體,從這個樣本團體的得分情形,計算出測驗的信度、效度,並且將之進行描述統計以建立常模。
這個依據所有受試者的作答結果所製作出來的常模是為全體常模,然而許多測驗手冊中列出的常模不只全體常模,測驗編製者會依據需要製作出不同團體的常模。
(一)全國性常模與地區性常模
1. 全國性常模(national norm):在樣本團體中有來自全國各地的受試者,若不分區域的將所有受試者進行描述統計而製作出來的常模,稱作全國性常模(也就是全體常模)。
2. 地區性常模(local norm): 將受試者區分不同區域,分別地進行描述統而製作出來的常模,就是地區性常模。
(二) 次團體常模(subgroup norms)
係指依據人口學(dempgraphic,如種族、性別、年齡、學歷、職業、居住地等)上可供辨認的次團體所建立的常模稱之。若測驗關切之特質有可見的差異(種族差異性別差異等) , 測驗編製者應依據次團體建立次團體常模,例如除全體常模之外,測驗編製者也應提供男性的常模和女性的常模。
只有在上述變項上,不同群體的測驗平均分數有顯著差異時,才提供分組常模,否則就直接使用整體常模即可。
只用整體常模或只用分組常模進行解釋 ,端看施測目的而定。在很多情況下,整體常模和分組常模同時使用,更能夠增進測驗的解釋力。例如,在美術性向測驗上,告知學生他在全國常模上百分等級是70,但在美術班上的百分等級是30。
1. 特殊團體常模
特殊團體常模(Special group norms)可以分成兩類,一類是特殊教育中所需要的「特殊學生常模」,這類學生常因為生理上的障礙(如;視障聽障)而修改了標準化施測程序,自然不宜與正常學生相互比較,因此有必要為相同條件的學生另建常模。
另一類則是指進行職業輔導時所用的「特定職業常模」。測驗編製者為了要讓輔導人員能夠明確說明某人的測驗結果最適於從事某一種職業,他必須找一群某一特定職業的資深從業人員進行人格、興趣和性向測驗,並找出最適於該職業的人格特質或興趣、性向組型;解釋時輔導人員將學生的各種測驗結果和特定職業常模相比對看他較適合從事哪一種職業。
2. 使用者常模
使用者常模(User norms)是以在某一特定時間實際接受這一測驗的人為樣本所建立的常模。例如,台灣的國民中學學生基本學力測驗每一年所用的百分等級常模就是使用者常模。
使用者常模是一種便利取樣的常模,它並不事先計畫要代表某個界定好的母群體,所以使用時要伴隨著對於樣本的詳細描述。
(三)以常模表的排列格式來分
常模表(Norms tables)常附於測驗指導手冊之後,以供測驗使用者將原始分數換算成標準化分數或百分等級,常模表依據資料的排列方式可分成下列數種:
1. 簡單常模表
簡單常模表(Simple norms tables) 只有一欄原始分數和一欄衍生分數的常模表。它在形式上是最簡單,但在印刷上及查表時間上卻最不經濟。
2. 多組別共用的常模表
若是將依據不同組別(年級、性別)建立的常模合併在一個表上來使用,將會呈現有一欄原始分數,而有多欄不同組別的衍生分數。這種多組別共用的常模表(Multiple-group norms tables),可以使一種衍生分數只需要一張表,不但減少印刷成本,也比較容易看出同一個原始分數在不同組別中的相對地位。
3. 多種分測驗共用的常模表
若是一套測驗中含有多個分測驗(如綜合性向、綜合成就測驗),或是能算出多種分數(如診斷測驗、多因素人格測驗)時,則可以把同年齡組同一衍生分數的不同分測驗的常模表合併在一起,稱之為多種分測驗共用的常模表(Multiple-subtests norms tables) ,這樣使用者可以使用一張表就查出受測者在不同分測驗上的同一種衍生分數。
這種常模表不只是節省印刷成本,而且查表時不必常翻頁,效率較高,非常適合用在綜合性向測驗上。但如果分測驗之間,題數差距很大就不適合併在一起呈現出來。
4. 多種衍生分數共用常模表
若是一套測驗中能算出多種衍生分數(如百分等級、標準九)時,則可以把同年齡組的不同衍生分數的常模表合併在一起,稱為多種衍生分數共用常模表(Multiple-score norms tables),這樣使用者可用一張表就查出受測者的同一分測驗的所有衍生分數。這種常模表不只是節省印刷成本,而且查表時不必常翻頁,效率較高(其形式類似附錄一的對照表)。
5. 簡略式常模表
當原始分數全距太大時,而且不同的鄰近分數常換算出相同的衍生分數時(如速度測驗),有些編製者會以等間隔的方式,只取部份原始分數(如,0, 5, 10, 15, 20,…)來建立簡略式常模表(Abbreviated norms tables) 。使用者若遇到未呈現出來的原始分數分數,就得自己用內插法求出衍生分數。這種常模表雖然省了印刷成本,但增加使用者的查表時間和計算工作,且容易造成錯誤,不值得鼓勵。
6. 濃縮式常模表
濃縮式常模表(Condensed norms tables)和上述簡略式常模表很像,只不過是它將衍生分數做等間隔的部份呈現(通常是百分等級,如,1, 3, 5, 10, 15,…)。在該測驗並不需要做精細比較時,使用這種常模表即可。